
A good database design provides the best performance during data manipulation which results in the best performance of an application.
During database designing and data manipulation we should consider the following key points:
1). Make sure that every table in your database has a primary key :
This will ensure that every table has a clustered index created. So, any data retrieval operation from the table using the primary key, or any sorting operation on the primary key field or any range of primary key values specified in the where clause will retrieve data from the table very fast.
2). Create non-clustered indexes on columns which are :
- Frequently used in the search criteria
- Used to join other tables
- Used as foreign key fields Of having high selectivity (column which returns a low percentage (0-5%) of rows from a total number of rows on a particular value)
- Used in the ORDER BY clause
- Columns of type XML (primary and secondary indexes need to be created)
3). Choose Appropriate Data Type:
Choose appropriate SQL Data Type to store your data since it also helps in to improve the query performance.
4). Avoid * in SELECT statement:
Practice to avoid * in the SELECT statement since SQL Server converts the * to columns name before query execution. One more thing, instead of querying all columns by using * in the SELECT statement, give the name of columns which you required.
5). Use Table variable in place of Temp table
Use Table variable in place of Temp table since Temp table resides in the TempDb database. Hence the use of Temp tables required interaction with TempDb database that is a little bit time-taking the task.
6). Avoid prefix “sp_” with user defined stored procedure name :
Avoid prefix “sp_” with user defined stored procedure name since system defined stored procedure name starts with prefix “sp_”. Hence SQL server first searches the user defined procedure in the master database and after that in the current session database. This is time-consuming and may give unexpected result if system defined stored procedure have the same name as your defined procedure.
7). Use EXISTS instead of IN :
Practice to use EXISTS to check existence instead of IN since EXISTS is faster than IN.
8). Does my record exist?
If you want to check if a record exists, use EXISTS() instead of COUNT(). While COUNT() scans the entire table, counting up all entries matching your condition, EXISTS() will exit as soon as it sees the result it needs.
9). Avoid Functions on the Left-Hand-Side of the Operator :
Functions are a handy way to provide complex tasks and they can be used both in the SELECT clause and in the WHERE clause. Nevertheless, their application in WHERE clauses may result in major performance issues. Take a look at the following example: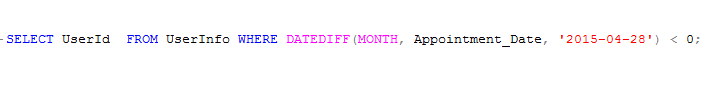
The above ex. will be too expensive because the output of the function is evaluated at run time, so the server has to visit all the rows in the table to retrieve the necessary data. To enhance performance, the following change can be made:

10). Use column names while writing Insert query
Use column names while writing Insert statement because if in future any column will be added then your query will give an error.

11). Use CTE instead Temp:
Use CTE if we need to cache large data into a temp table for short time single query.
12). Index vs Covering Index:
Use covering index when we need to fetch a set of fields together in a single query.
13). [dbo].tableName :
Try to use [dbo].tableName in query.
14). No Count On :
Use No Count On in the starting of the procedure.

Anurag Saxena!!

